


Cele mai multe companii moderne isi bazeaza activitatea intr-o proportie covarsitoare pe buna functionare a infrastructurii de retea. Daca apare downtime, acesta aduce cu sine imposibilitatea organizatiei de a-si deservi angajatii si clientii, pierderi financiare si afectarea capabilitatii de a face business (impact asupra reputatiei companiei). Bunul mers al retelei este, deci, o functie vitala pe care departamentul IT de suport trebuie sa o ofere companiei.
Cu cat inginerii de suport diagnosticheaza si rezolva problemele mai eficient, cu atat impactul asupra business-ului va fi mai mic. In retele enterprise complexe, a face troubeshooting devine usor o problema complexa. Se recomanda o abordare metodica pentru a rezolva rapid problemele, abordare care se bazeaza pe proceduri bine definite si pe o documentatie a retelei completa si la zi.
Procesul de troubleshooting
Procesul de troubleshooting sau de depanare a retelelor nu este o stiinta precisa, adeseori o problema putand fiind diagnostica si chiar rezolvata in moduri diferite. O abordare ad hoc a problemei bazata pe intuitie sau pe o banuiala poate reprezenta o solutie, insa o metodologie structurata ii permite celui care executa procesul de depanare sa isi dezvolte acest skill si sa gaseasca o rezolvare mult mai rapida. In domeniul retelisticii sunt mai multe tipuri de metodologii structurate. Pentru unele probleme, una dintre aceste metode merge cel mai bine. Pentru alte probleme, poate o alta metoda este mai potrivita. De aceea, este important pentru inginerul care face troubleshooting sa fie familiar cu toate aceste metode si sa selecteze acea metoda sau combinatie de metode prin care sa rezolve o anumita problema.
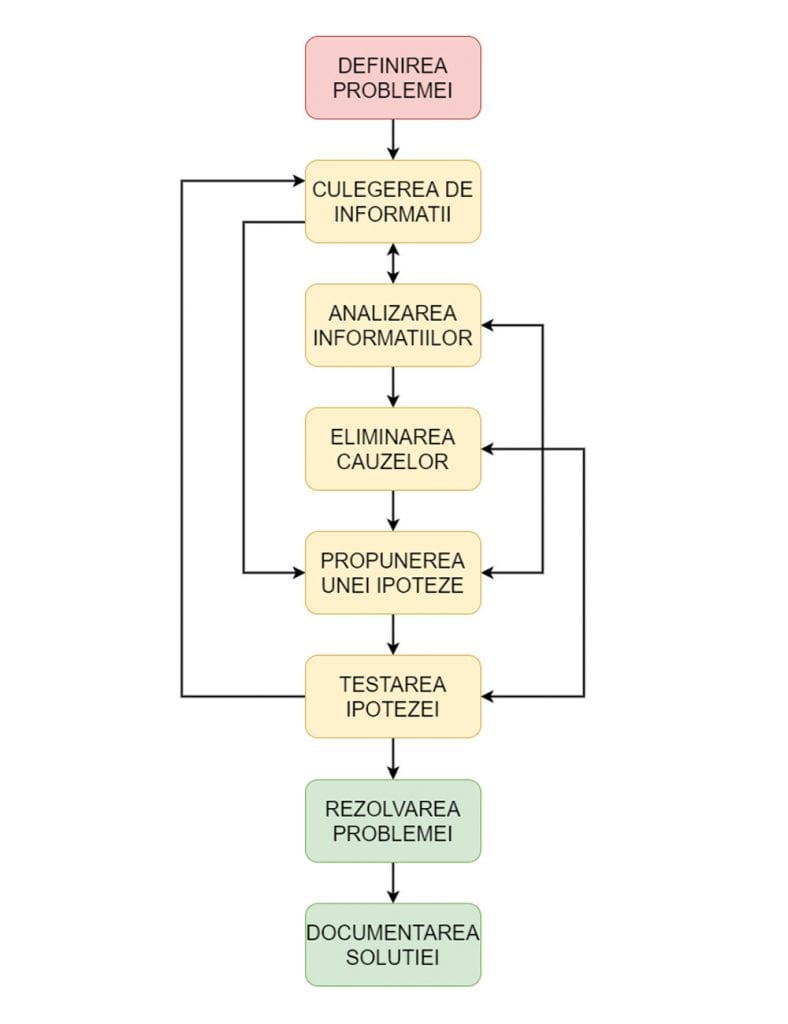
O abordare structurata a procesului de troubleshooting serveste ca un ghid de “how-to” pentru persoana care depaneaza problema. Ideea de baza din spatele procesului este de a elimina sistematic cauzele improbabile si de concentra eforturile asupra cauzelor probabile. Apoi, tot printr-o abordare sistematica se elimina cauzele probabile pana cand se reuseste izolarea si rezolvarea problemei. Documentarea pasilor urmati in procesul de troubleshooting este de mare ajutor in cazul in care problema este transmisa mai departe catre o alta persoana, mai ales daca se lucreaza intr-un departament de suport Level 1 – Level 2 de tipul “follow the sun”. Avand deja informatii colectate despre problema si testarea unor ipoteze inseamna ca nu este nevoie ca procesul de troubleshooting sa fie reluat de la zero.
Abordari structurate de troubleshooting
Cateva dintre cele mai comune abordari metode de depanare sunt:
- abordarea top-down: aceasta abordare presupune urmarirea modelului OSI de sus in jos, incepand cu nivelul aplicatie pana la nivelul fizic. Problemele raportate de utilizatori sunt probleme de nivel aplicatie: nu pot accesa un anumit site web, asa ca inceperea depanarii la acest nivel este naturala. Totusi, s-ar putea ca departamentul IT sa nu aiba acces la software-ul aplicatii care are probleme, deci va trebui “mers” (fizic sau virtual) la client si testate ipotezele posibile.
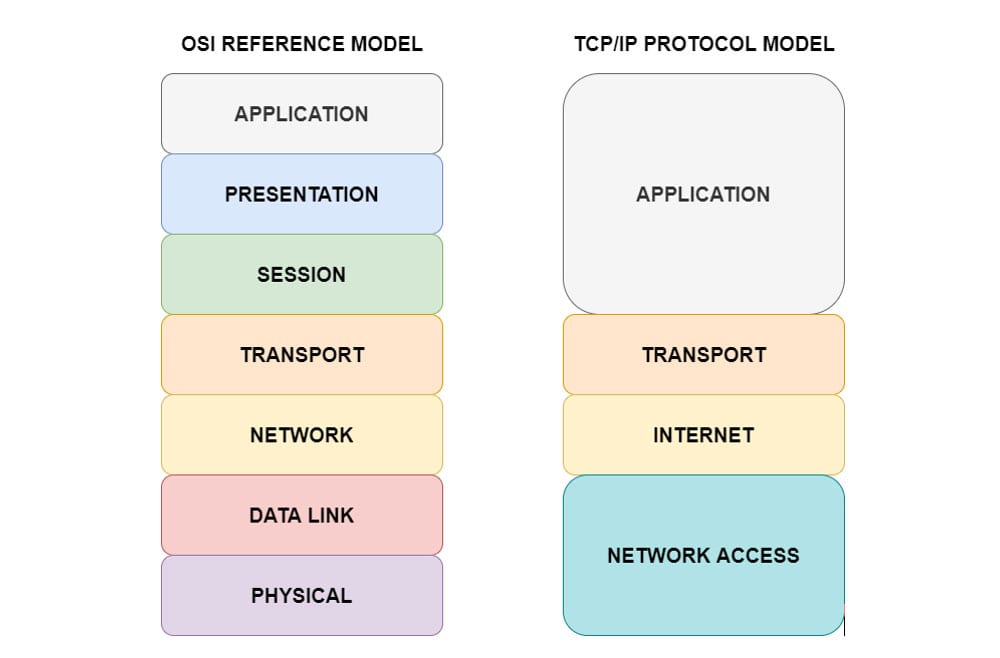
- abordarea bottom-up: aceasta abordare incepe cu verificarea nivelului fizic din modelul OSI continuand pana la nivelul aplicatie. Avantajul acestei metode este acela ca se pleaca cu depanarea din retea, accesul la dispozitivul clientului sau la aplicatia software nefiind inca necesar, si poate nu va fi necesar niciodata. Multe probleme tin de primele nivele de jos in sus din stiva OSI: cablu deconectat, placa wireless inchisa, port de switch configurat intr-un VLAN gresit, adrese IP indisponibile in pool de DHCP si lista poate continua.
- divide et impera: aceasta strategie incepe procesul de troubleshooting de obicei la nivelul retea din modelul OSI, si, pe baza anumitor teste, procesul continua fie inspre nivelul aplicatie, fie spre nivelul fizic. Cele mai elementare teste care se pot face sunt testele de ping si de traceroute. Daca aceste teste sunt facute cu succes, atunci problema este mai sus de nivelul retea. Daca aceste teste esueaza, poate fi o problema la nivelul retea, legatura de date sau la nivelul fizic.
- follow the path: aceasta metoda se bazeaza pe calea pe care pachetele o urmeaza in drumul lor de la sursa la destinatie. O buna documentare a retelei, o schema de Layer 2 care ilustreza topologia de STP si o schema de Layer 3 care indica topologie de rutare sunt deosebit de importante in aceasta metoda de troubleshooting. O alta resursa importanta este un baseline al retelei prin care se reliefeaza care sunt caile de trimiterea a traficului (traffic paths) de la sursa la destinatie pe care reteaua le foloseste in conditii de functionare normala, corecta.
- spot the differences: aceasta abordare presupune comparea configuratiilor echipamentelor de retea sau a protocoalelor care functioneaza corect cu cele ale echipamentelor care nu functioneaza asa cum ar trebui pentru a obtine indicii despre nepotriviri de parametrii, greseli de configurare sau lipsa unor comenzi. De asemenea, versiunile de software pot fi diferite, si anumite feature-uri sa nu functioneze corect sau sa existe buguri in codul sursa.
- move the problem: aceasta metoda implica mutarea unui element fizic din retea (cablu, echipament, poate chiar componenta – de exemplu SFP, supervizor, sursa de alimentare, placa de retea) intr-o alta zona sau echipament pentru a vedea daca problema se muta odata cu elementul respectiv sau nu.
Toate metodele de troubleshooting se bazeaza pe etapele de strangere de informatii si analiza acestora, pe eliminarea cauzelor probabile, pe formularea de ipoteze si pe testarea acestora. Fiecare etapa dintre aceastea are meritele sale si necesita petrecerea unui anume timp si consumarea unor resurse. Cum si cand o persoana trece de la o etapa la alta este un factor cheie in masurarea succesului procesului de depanare.
Mihai Dumitrascu, Sr Systems Engineer

{kind=link}